Incident OVHCloud / incendie / destruction d’un datacenter : journal de bord

Bonjour les amis, j’espère que vous allez bien. Nous sommes le dimanche 28 mars 2021, cela fait maintenant 18 jours qu’a eu lieu un événement qui a affecté, non seulement sa principale victime, OVHCloud, mais également les clients et partenaires directs et indirects qui utilisaient ou exploitaient ces infrastructures.
Pour ceux qui n’auraient pas le courage de tout lire, j’ai également enregistré cet article sous forme de podcast audio ici : https://spreaker.com/episode/44088041
Il est également disponible sur YouTube :
La situation étant un peu plus calme, j’en profite pour écrire un petit billet sur ce sujet, et vous relater dans les grandes lignes, comment j’ai vécu cet incident, aussi bien du point de vue opérationnel qu’émotionnel. J’essaie ici d’être aussi transparent qu’il me soit possible de l’être, tout en respectant les contrats qui lient mes activités auprès à la fois des clients, des partenaires et des fournisseurs.
Vous pourrez constater une différence d’une heure sur les « copier/coller », car en ce qui me concerne personnellement, je réside en Irlande. J’ai aussi effacé les informations des captures qui contiennent des données privées permettant par exemple d’identifier un client, etc.
Les alertes arrivent principalement par 3 vecteurs de communication : Pushover sur les téléphones, par email, ainsi que sur un canal dédié aux alertes sur Telegram.
01H12 : Une première alerte tombe, elle concerne un client du service MIS, l’activité d’infrastructures et de serveurs managés d’OVHCloud pour laquelle Digital Network est partenaire intégré et s’occupe à ce titre de la partie commerciale et technique.
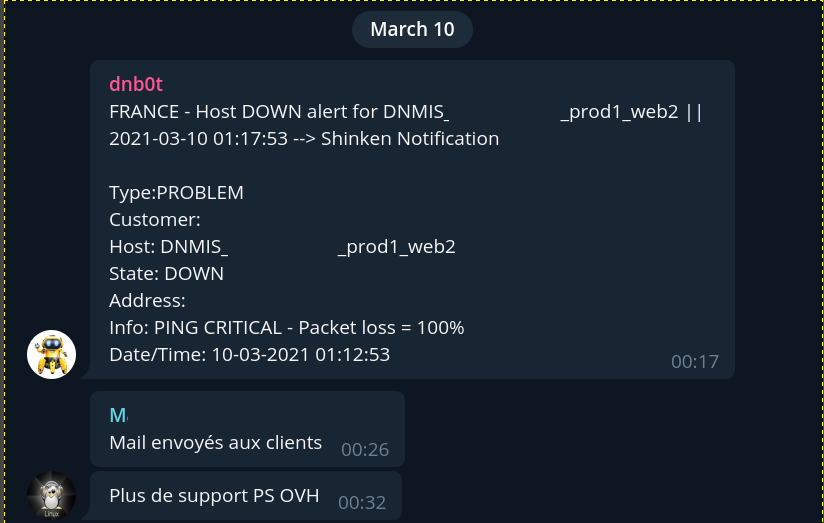
Il s’agit seulement d’une machine qui ne ping plus, généralement la rootcause est anodine : incident électrique, réseau ou hardware du serveur. Rien de grave ici : il s’agit d’une infrastructure haute disponibilité : les services du client restent disponibles, il n’y a pas de coupure de service. Le process est simple -> analyse rapide, email envoyé au client pour le prévenir de l’incident, vérification plus en détail coté API : rien qui suggère un arrêt suite à un défaut de paiement, pas de réponse coté KVM, la machine ne veut pas rebooter, le technicien d’astreinte tente de joindre le support Entreprise mais en vain.
01H40 : Une seconde alerte arrive, il s’agit du serveur shinken dont nous avons hérité et qui est en charge du monitoring des infrastructures MIS « Legacy », c’est à dire qui ne monitore que les infrastructures Legacy qui sont étiquetées « obsolètes » mais que les clients n’ont pas encore pu ou voulu migrer pour un tas de raisons qui leurs sont propres (je reviendrai un jour sur la gestion de l’obsolescence).
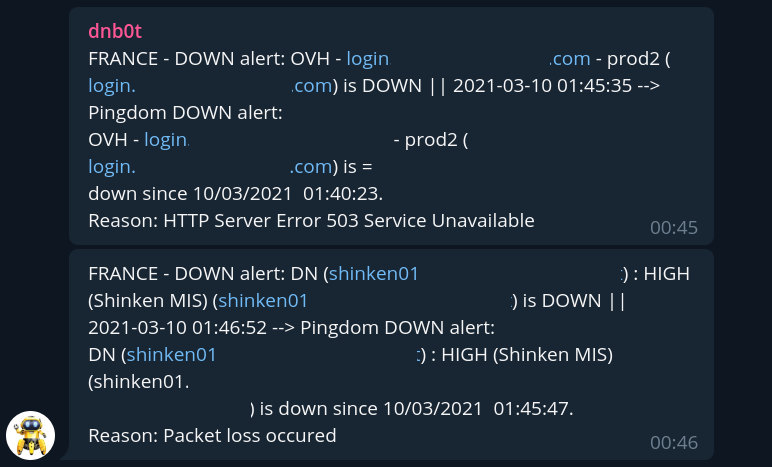
Là encore, rien de vraiment dramatique : cet incident se produit de manière récurrente depuis quelques semaines lorsque le backup automatique OVH des instances PCI tourne sur la machine, un ticket est déjà ouvert à ce sujet. On sait que la machine revient ensuite dès que le backup est terminé, et les infrastructures legacy sensibles disposent également d’un autre monitoring externe via pingdom.
02H11 : Une alerte tombe concernant un client cloud DN (dont les infrastructures sont construites chez OVH à base de bare-metal et réparties équitablement au sein des sites de Roubaix, Gravelines et Strasbourg. Je ne suis pas couché, et je suis entrain de travailler, du coup j’informe le support que je m’occupe de vérifier ce client.
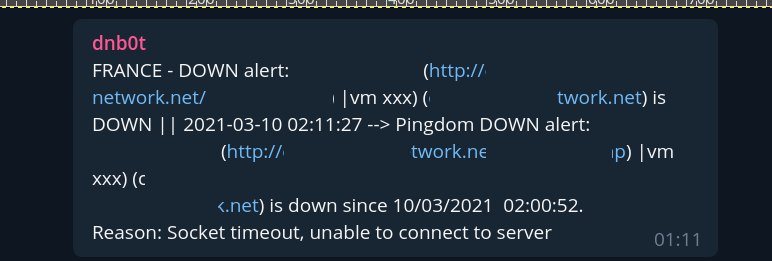
A ce moment là je constate que la machine est entrain d’être backupée (vzdump en cours depuis Proxmox VE vers un serveur de backup NFS), et que le backup semble avoir du mal, apparemment la connexion vers le serveur de stockage correspondant est en souffrance. Je décide de couper la task, la machine n’a pas l’air très bien, je la dévérouille puis je la redémarre, un petit check : à 2H16 elle est de nouveau up.
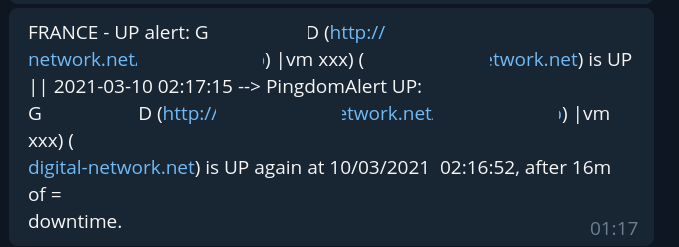
Quelques minutes après un autre down client concernant les infrastructures du cloud DN arrive suivi d’indication de down complet des infrastructures de backup correspondantes :
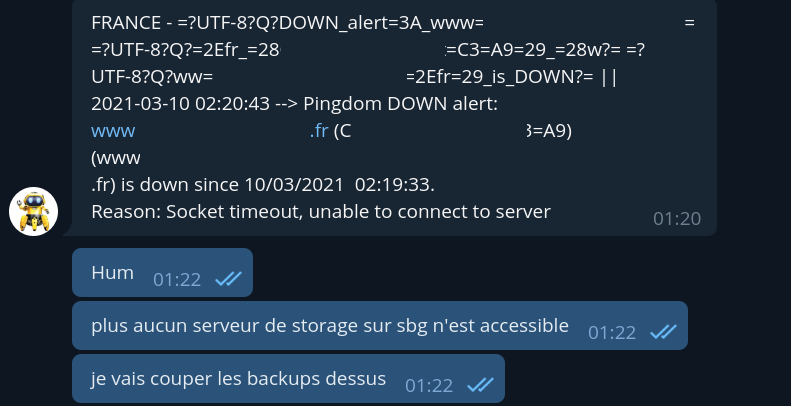
Je fais quelques vérifications manuelles et je constate que plus aucun de nos serveurs de storage sur SBG2 n’est accessible. Je prends la décision de couper tous les backups en cours au niveau hyperviseur sur SBG. (le système de backup sur les machines elles-mêmes, qui utilise lui rdiff-backup, n’impacte pas les performances ou la disponibilité des machines en cas de non accessibilité).
2H19 : ça commence à devenir sérieux. Les alertes commencent à tomber par centaines.
Le site de travaux d’OVH indique bien un incident et qui concerne les services de 2 salles sur SBG qui correspondent à notre problème, du coup là encore, inutile de s’inquiéter outre mesure : je pense à un incident réseau ou électrique important. Mais on est en pleine nuit, l’impact client reste négligeable, je reste zen.
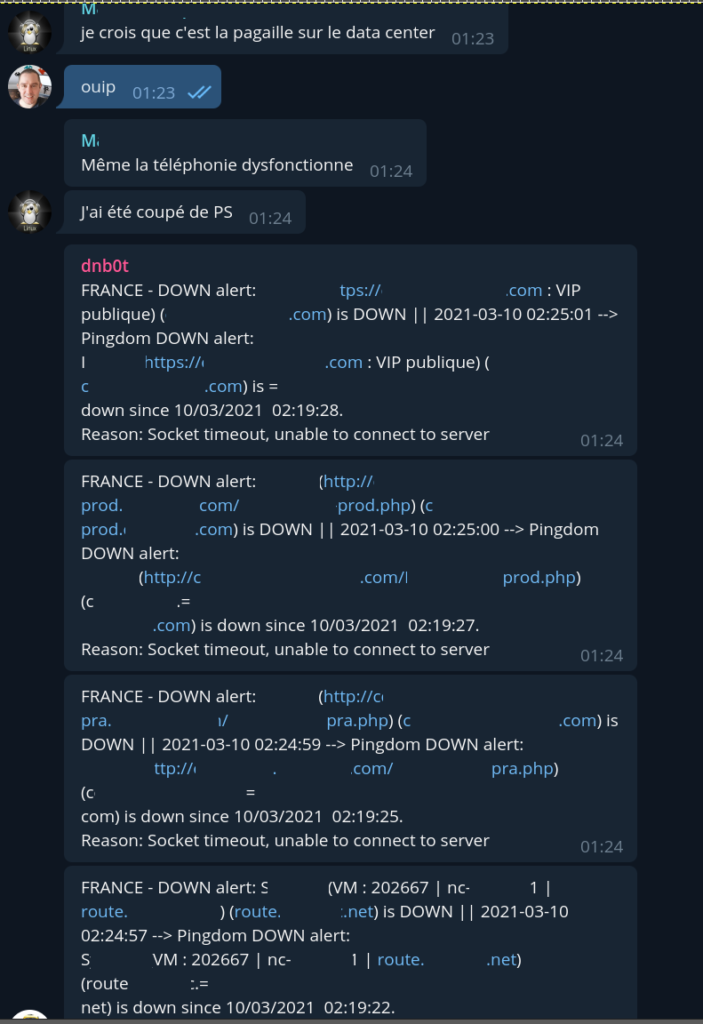
En parallèle de cela j’informe les clients de cet incident général via les différents canaux dédiés à cet effet.
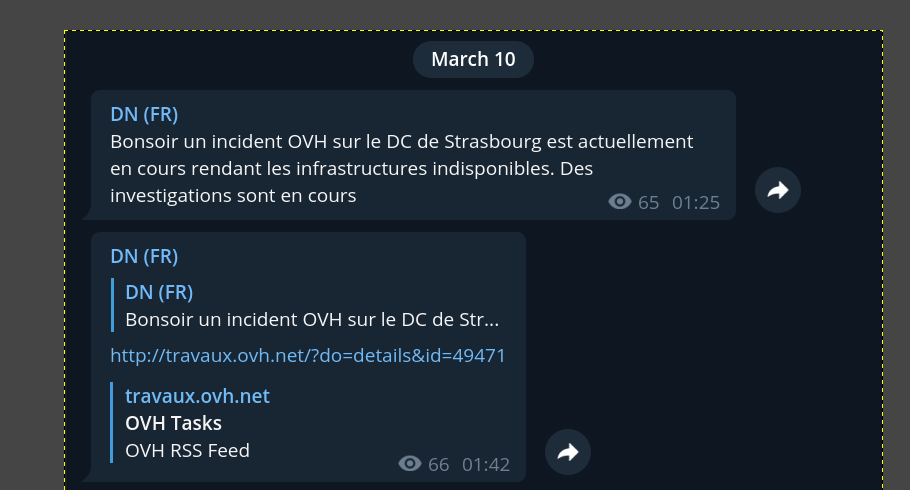
Ne pouvant rien faire de plus pour l’instant, je décide d’aller me coucher, je garde le téléphone près de moi pour être informé du retour à la normale et pouvoir effectuer quelques diagnostics par précaution… le temps passe. Il est plus de 5H00 du matin et toujours rien, je décide de faire quelques checks depuis mon lit via mon phone et ma tablette.
Et c’est là, alors que je suis entrain d’effectuer différents diagnostics depuis à la fois l’extérieur, d’autres Datacenters, au travers à la fois du réseau public et du vRack, que la personne d’astreinte va poster sur un canal Telegram les informations suivantes :
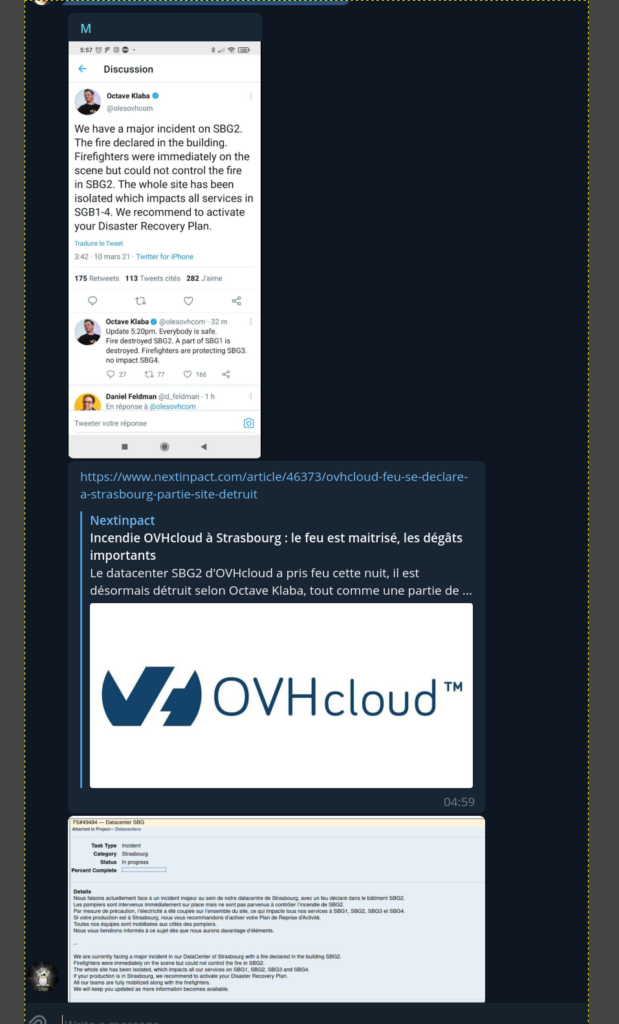
Alors il faut savoir que j’ai l’habitude depuis de longues années de gérer à peu près n’importe quelle situation de crise avec une impassibilité qui a le don de rendre les autres fous. Mais le plus souvent ce sont les crises des autres que je gère, elles ne m’affectent que rarement directement même si des situations similaires me sont déjà arrivé 3 ou 4 fois au cours de ces 22 dernières années.
Ni une ni deux, je saute du lit d’un bond, et je file en courant dans mon bureau où 4 postes sont allumés 24/7. Je m’assois devant mon poste principal, et je clique en premier sur le lien de NextInpact. J’ai regardé tout d’abord la date : serait-on le premier avril ? Puis avant de lire l’article, je file directement à la fin pour voir s’il ne s’agit pas d’un premier avril avant l’heure… Puis je remonte et je vois la photo du bâtiment dont il ne reste qu’une carcasse ressemblant vaguement à un jouet en plastique qu’on aurait envoyé dans la cheminée.
A cet instant précis, durant peut être 7 ou 8 minutes, je me suis senti défaillir. A 5H36 j’écris sur le canal « Non mais c’est la fin là« . Pour être totalement honnête, devant les photos qui circulaient déjà, j’avais les larmes aux yeux. OVH n’est pas ma société mais c’est un partenaire historique. J’ai eu mon premier serveur aux tous débuts d’OVH. Je crois savoir qu’il s’agit de l’un des 5 serveurs que l’on voit en bas à gauche de cette photo. Serveur qui plus tard, me sera envoyé par transporteur mais que je n’ai malheureusement pas gardé.

binary comment
Je suis allé réveiller ma chère et tendre épouse qui est également mon associée depuis 1999, j’avais les yeux légèrement embués et je lui dis : un datacenter a cramé. Sur le moment elle pense à un simple « gros problème » de datacenter, et là je lui précise : non mais je veux dire il a vraiment cramé, il ne reste qu’un tas de cendres !
3 ou 4 minutes se passent, il est temps de se poser, de se ressaisir, et de retourner au combat.
Plusieurs sources m’indiquent que SBG1 et 2 seraient détruits (on découvrira plus tard que seule une partie de SBG1 a été détruite), que SBG3 n’a pas été endommagé, mais qu’on ne sait pas, du fait de l’énorme coup de chaud provoqué par un tel incendie, dans quel état les infrastructures qui s’y trouvent vont être récupérées…

Comme le montre cette photo et d’autres que vous avez peut être pu voir sur Internet, l’incendie était particulièrement impressionnant…
A 7H00 au vue de l’ampleur des dégats, je décide d’activer, sans attendre de validation client, l’ensemble des PRA (plans de reprise d’activités, même si là il s’agit en réalité davantage de PSI, un PRA s’étendant à l’ensemble des activités métier de l’entreprise) pour tous ceux qui sont impactés par l’incident et qui disposent de cette option… Pour les autres qui disposaient de services suffisamment simples pour bénéficier d’un système de répartition des requêtes avec un secours actif : ils ne se sont même pas rendu compte de l’incident…
Quelques minutes après, les services concernés sont up, même si un des clients, particulièrement sensible et où des dizaines de milliers de personnes d’institutions bancaires travaillent sur son application SaaS, devra faire quelques manipulations complémentaires de son coté pour finaliser la complète remise en service. Extrait des remontées :
Les premiers inventaires sont rapidement effectués à la fois concernant Digital Network, ScalarX et MIS :
– Coté ScalarX : tous les clients concernés disposaient d’infrastructures redondantes, et aucun backup n’a été perdu. Les infrastructures de pilotage de ScalarX étant situées dans le DC de Londres, tout est donc opérationnel à 100%
– Coté DN : si on retire les infrastructures qui disposaient d’une option de PRA. Environ 33% des infrastructures de production client sont down. Pour 85% de ces 33% les backups sont disponibles(dont une partie à cause / grâce à une erreur de code que j’ai faite au mois de décembre, j’y reviendrai). Nos infrastructures internes sont toutes opérationnelles, plus aucune n’était située à SBG.
– Coté MIS : c’est plus mitigé, certains sont partiellement atteints, mais quelques clients ont perdu à la fois les infrastructures et leurs backups. Coté infrastructures internes, des backups sont perdus, ainsi que (temporairement ou définitivement, je ne sais pas encore, réponse d’ici quelques jours au moment où j’écris ces lignes), l’infrastructure Legacy qui fait tourner les vieux clients. (Mais nous disposons de backups à jour de tout ce qui est données et bases de données).
– Les équipes priorisent ce qui peut l’être. On se synchronise avec OVH pour remplacer les infrastructures détruites qui peuvent l’être sur d’autres Datacenter, mais la supply chain va rapidement se retrouver en état de DDOS, face à l’énorme vague de demandes.
Les tickets et les appels pleuvent de tous les cotés. Je prends un max de tickets DN que j’expédie avec un simple copier / coller -> l’incident est général, il doit être traité de manière globale et ne peut pas être traité individuellement. Je m’occupe de traiter en direct via Telegram avec les clients plus « spéciaux », ceux qui doivent l’être en même temps que les équipes s’affairent à essayer d’endiguer la vague de demandes.
Coté DN, je me retrouve principalement avec deux cas :
– Les clients pour qui nous avons un backup mais qui préfèrent attendre le redémarrage.
– Les clients pour qui nous avons un backup et ne souhaitent pas attendre.
A noter quelque chose d’extraordinaire : certains clients ont demandé à figurer « en bas de la liste« , parce qu’ils considèraient sur leurs infrastructures n’étaient pas vitales au regard de certaines autres activités d’autres clients. Une telle abnégation force le respect.
Les gens qui ne sont pas du métier pensent qu’il suffit d’un backup et « ça repart », mais dans la pratique les choses sont plus compliquées, surtout lorsque le client dispose du root et fait ses trucs un peu comme il le souhaite. Cette partie est vraiment quelque chose que je maitrîse très profondémment, j’ai déjà migré des salles serveurs complètes, effectué des migrations entre des environnements très différents : je sais comment aller très vite.
Je laisse au support DN la continuité du traitement des tickets standards, car il y a encore 2 DC qui tournent, et je passe en mode flow. Je regènère rapidement toutes les infrastructures, puis les environnements des clients (Merci le bash). Pour ceux pour qui les environnements vont changer, j’écris rapidement des « drivers » en bash, chargés de traduire l’ensemble des correspondances et de les faire marcher.
L’idée est que le client n’est quasi aucune action à faire de son coté. Ainsi lorsque les anciens accès ne peuvent être récupérés, les nouveaux sont mis à jour automatiquement dans le code des sites et applications des clients. Bien entendu il y a quelques limites techniques qui se posent : du aux incidents les connexions réseau ne sont pas forcément optimales, et (sauf pour les clients diposant de backups dédiés), lorsque vous sollicitez plusieurs dizaines ou centaines de backups en même temps sur un serveur, ce dernier ne va pas vous délivrer les données à la même vitesse que lorsque vous n’en sollicitez qu’un seul (ce qui se passe en temps d’exploitation « normal »).
Bref, tout ce qui peut repartir repart. En parallèle on me remonte quelques cas particulièrement difficiles / critiques sur MIS : on dispose des backups mais les infrastructures pour réinstaller les clients ne sont pas disponibles, et pour certains d’entre eux, s’ils n’ont pas de solution ils devront en trouver une ailleurs. Je fais alors le choix de mobiliser des infrastructures DN pour livrer ces clients.
Petit souci : il y a des différences fondamentales entre les infrastructures DN et MIS. Mise à part des versions de logiciel, l’arborescence, les droits, etc. Rien n’est pareil, les deux concepts partant de paradigmes différents. Je préviens les clients concernés, je leur explique ce que je peux faire pour eux, quels seront les impacts ou les limites -> ça valide.
A partir de là, même travail que plus haut, grands remerciements au Dieu BASH : pour ne pas que les clients aient besoin de comprendre ce nouvel environnement et après avoir compris leur organisation, je repasse en mode flow : écriture de systèmes permettant de régénérer tous les environnements clients, et les profils sont très différents, cela peut aller de 1 site à plus de 1500 vhosts avec autant de SSL à générer.
Certains disposent des données et de dumps de base de données, mais ont perdu toutes les configurations vhost -> après discussion on découvre des solutions adaptées à chacun : récupérer le nom du vhost dans la base de données par exemple, etc. Les clients concernés sont remis en service de cette manière, le temps que leurs nouvelles ou anciennes infrastructures, soient disponibles à nouveau (pour l’instant, au moment où j’écris ils sont toujours dans ce mode).
(J’ai pensé durant un instant enregistrer tout cela, et voir comment j’aurai pu en faire une vidéo, mais vraiment il s’agissait à 90% du temps de manipulation de données qui ne pouvaient être montrées car contenant toutes des informations privées appartenant aux clients, etc. Intérêt limité que celui de montrer un écran sans arrêt flouté.)
Après cela j’ai décidé de consacrer mon temps à aider à faire la même chose pour des gens qui n’étaient pas clients. Mise à disposition à titre gracieux d’infrastructures temporaires, aider ceux qui pensent avoir tout perdu en leur donnant des pistes de récupération telles que j’en évoquais dans mon précédent live, pour ceux que cela intéresse, il est disponible ici :
Alors je ne peux pas décrire chacun de ces jours, car cela me prendrait la taille de livre. Il y a eu entre temps cet incident électrique majeur à Gravelines à l’échelle d’une salle qui est venu m’exploser des clients qui tournaient déjà sur PRA, etc. Les plus gros problèmes n’arrivent que rarement seuls… Bref, pour chaque problème une nouvelle solution apparait et est mise en place.
En parallèle OVHcloud commence à me livrer des infrastructures : j’en profite pour remonter des infrastructures + backup qui seront capables d’accueillir ce qui est resté sur SBG3 dès l’allumage. J’ai assez rapidement pris cette décision : j’ai déjà connu par le passé de gros sinistres Datacenter (électriques, inondations, etc.) et même si jamais aucun autre n’avait eu un tel impact (notamment la destruction physique sans possibilité de récupération de tous les équipements), par expérience, après un tel incident, le taux de risques sur l’infrastructure rallumée additionnés aux problèmes réseaux à reconstruire, temps pour remettre en place les vracks multi-dc, etc. un enfer se prépare : j’informe tous les clients qu’ils ne seront pas rallumés lorsque SBG3 sera à nouveau disponible. Ils seront migrés sur une nouvelle infrastructure à RBX avant rallumage.
C’était finalement le bon choix, car toutes les ips publiques de mes plages sont routées via le vRack, et ce dernier n’était toujours pas fonctionnel vers l’extérieur la dernière fois que j’ai regardé. Je migre l’ensemble des clients qui étaient encore éteints puis je les rallume -> grands moments de joie ou de soulagement pour certains : aucune production n’a été perdue.
C’est ce que je vais vous dire maintenant qui va probablement le plus vous étonner… Si ce n’est les conséquences à la fois financières et techniques pour les clients : c’est pour ces moments là que je fais ce métier, et j’aime ces moments là. Alors bien sûr je préfère quand je les traite en externe, comme un prestataire, mais j’y ai malgré tout pris un immense plaisir. C’est dans ces moments de crise qu’on acquiert une expérience que nul autre ne pourra acquérir sans vivre la même chose : c’est dans ces moments là que l’on se dépasse, et que l’on devient meilleur, et c’est dans ces moments là que oui, je suis obligé de l’avouer : je m’éclate le plus !
Alors certes j’ai passé plus de 15 jours à travailler de 18 à 20H00 par jour, si on retire les 2H30 de sommeil quotidien, plus le temps passé à se déplacer dans la maison de la cuisine à la salle de bain, au bureau, le temps passé au téléphone, etc. et c’est avec le sourire ainsi qu’une certaine fierté, à plus de 45 ans et atteint d’une maladie auto-immune assez invalidante que je me retourne vers ces 15 derniers jours.
Petite note complémentaire : j’avais ma biothérapie le 11 Mars au matin, 24H00 après l’incident, et en général cette dernière me mets HS durant quelques jours. Je ne me suis arrêté de travailler que le temps du trajet (où je répondais cependant aux clients via Telegram) et j’ai repris le travail dès mon arrivée à l’hopital et dès mon retour à la maison ensuite sans broncher. ça fait du bien de voir qu’on est encore capable de relever ce genre de défis non consentis !

Voilà, je vais arrêter là avec ce petit retour d’expérience : je m’étais dit que je ne devais pas dépasser 2500 mots pour rester digeste, et je vois que j’ai dépassé les 2900. Je vous dis à tous : à bientôt !
Christophe Casalegno
Vous pouvez me suivre sur : Twitter | Facebook | Linkedin | Telegram | Youtube | Twitch | Discord
Laisser un commentaire